limit深度分页的坑
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
故事梅雨季,闷热的夜,令人窒息,窗外一道道闪电划破漆黑的夜幕,小猫塞着耳机听着恐怖小说,辗转反侧,终于睡意来了,然而挨千刀的手机早不振晚不振,偏偏这个时候振动了一下,一个激灵,没有按捺住对内容的好奇,点开了短信,卧槽?告警信息,原来是负责的服务出现慢查询了。小猫想起来,今天在下班之前上线了一个版本,由于新增了一个业务字段,所以小猫写了相关的刷数据的接口,在下班之前调用开始刷历史数据。 考虑到表的数据量比较大,一次性把数据全部读取出来然后在内存里面去刷新数据肯定是不现实的,所以小猫采用了分页查询的方式依次根据条件查询出结果,然后进行表数据的重置。没想到的是,数据量太大,分页的深度越来越深,渐渐地,慢查询也就暴露出来了。
强迫症小猫瞬间睡意全无,翻起来打开电脑开始解决问题。 那么为什么用使用limit之后会出现慢查询呢?接下来老猫和大家一起来剖析一下吧。
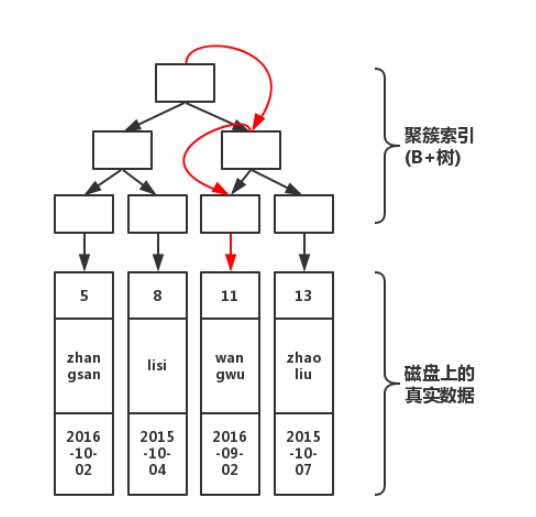
limit分页为什么会变慢?在解释为什么慢之前,咱们来重现一下小猫的慢查询场景。咱们从实际的例子推进。 做个小实验假设我们有一张这样的业务表,商品Product表。具体的建表语句如下: 从上述建表语句中我们发现timeCreated走普通索引。 当为浅分页的时候,如下: select * from Product where timeCreated > "2020-09-12 13:34:20" limit 0,10 此时执行的时间为: 当调整分页查询为深度分页之后,如下: select * from Product where timeCreated > "2020-09-12 13:34:20" limit 10000000,10 此时深度分页的查询时间为: 此时看到这里,小猫的场景已经重现了,此时深度分页的查询已经非常耗时。 剖析一下原因简单回顾一下普通索引和聚簇索引我们来回顾一下普通索引和聚簇索引(也有人叫做聚集索引)的关系。 大家可能都知道Mysql底层用的数据结构是B+tree(如果有不知道的伙伴可以自己了解一下为什么mysql底层是B+tree),B+tree索引其实可以分为两大类,一类是聚簇索引,另外一类是非聚集索引(即普通索引)。 (1)聚簇索引:InnoDB存储表是索引组织表,聚簇索引就是一种索引组织形式,聚簇索引叶子节点存放表中所有行数据记录的信息,所以经常会说索引即数据,数据即索引。当然这个是针对聚簇索引。
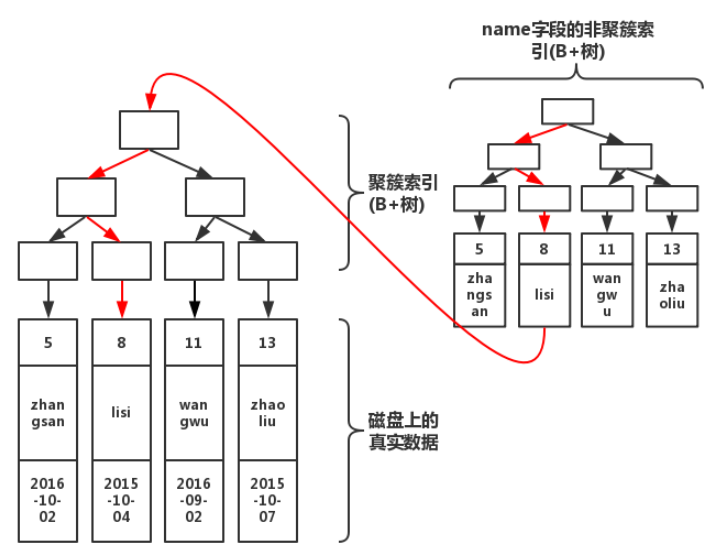
由图可知在执行查询的时候,从根节点开始共经历了3次查询即可找到真实数据。倘若没有聚簇索引的话,就需要在磁盘上进行逐个扫描,直至找到数据为止。显然,索引会加快查询速度,但是在写入数据的时候,由于需要维护这颗B+树,因此在写入过程中性能也会下降。 (2)普通索引:普通索引在叶子节点并不包含所有行的数据记录,只是会在叶子节点存本身的键值和主键的值,在检索数据的时候,通过普通索引子节点上的主键来获取想要找到的行数据记录。
由图可知流程,首先从非聚簇索引开始寻找聚簇索引,找到非聚簇索引上的聚簇索引后,就会到聚簇索引的B+树上进行查询,通过聚簇索引B+树找到完整的数据。该过程比较专业的叫法也被称为“回表”。 看一下实际深度分页执行过程有了以上的知识基础我们再来回过头看一下上述深度分页SQL的执行过程。 1、通过普通索引idx_timeCreated,过滤timeCreated,找到满足条件的记录ID; 2、通过ID,回到主键索引树,找到满足记录的行,然后取出展示的列(回表); 3、扫描满足条件的10000010行,然后扔掉前10000000行,返回。 结合看一下执行计划:
原因其实很清晰了: 再深入一点从底层存储来看,数据库表中行数据、索引都是以文件的形式存储到磁盘(硬盘)上的,而硬盘的速度相对来说要慢很多,存储引擎运行sql语句时,需要访问硬盘查询文件,然后返回数据给服务层。当返回的数据越多时,访问磁盘的次数就越多,就会越耗时。 替换limit分页的一些方案。上述我们其实已经搞清楚深度分页慢的原因了,总结为“无用回表次数过多”。 那怎么优化呢?相信大家应该都已经知道了,其核心当然是减少无用回表次数了。 有哪些方式可以帮助我们减少无用回表次数呢? 子查询法思路:如果把查询条件,转移回到主键索引树,那就不就可以减少回表次数了。 select * FROM Product where id >= (select p.id from Product p where p.timeCreated > "2020-09-12 13:34:20" limit 10000000, 1) LIMIT 10; 测试一下执行时间: 我们可以明显地看到相比之前的27499,时间整整缩短了十倍,在结合执行计划观察一下。
我们综合上述的执行计划可以看出,子查询 table p查询是用到了idx_timeCreated索引。首先在索引上拿到了聚集索引的主键ID,省去了回表操作,然后第二查询直接根据第一个查询的 ID往后再去查10个就可以了! 显然这种优化方式是有效的。 使用inner join方式进行优化这种优化的方式其实和子查询优化方法如出一辙,其本质优化思路和子查询法一样。 select * from Product p1 inner join (select p.id from Product p where p.timeCreated > "2020-09-12 13:34:20" limit 10000000,10) as p2 on p1.id = p2.id 测试一下执行的时间:
咱们发现和子查询的耗时其实差不多,该思路是先通过idx_timeCreated二级索引树查询到满足条件的主键ID,再与原表通过主键ID内连接,这样后面直接走了主键索引了,同时也减少了回表。 上面两种方式其核心优化思想都是减少回表次数进行优化处理。 标签记录法(锚点记录法)我们再来看下一种优化思路,上述深度分页慢原因我们也清楚了,一次性查询的数据太多也是问题,所以我们从这个点出发去优化,每次查询少量的数据。那么我们可以采用下面那种锚点记录的方式。类似船开到一个地方短暂停泊之后继续行驶,那么那个停泊的地方就是抛锚的地方,老猫喜欢用锚点标记来做比方,当然看到网上有其他的小伙伴称这种方式为标签记录法。其实意思也都差不多。 这种方式就是标记一下上次查询到哪一条了,下次再来查的时候,从该条开始往下扫描。我们直接看一下SQL: select * from Product p where p.timeCreated > "2020-09-12 13:34:20" and id>10000000 limit 10 显然,这种方式非常快,耗时如下: 但是这种方式显然是有缺陷的,大家想想如果我们的id不是连续的,或者说不是自增形式的,那么我们得到的数据就一定是不准确的。与此同时咱们也不能跳页查看,只能前后翻页。 当然存在相同的缺陷,我们还可以换一种写法。 select * from Product p where p.timeCreated > "2020-09-12 13:34:20" and id between 10000000 and 10000010 这种方式也是一样存在上述缺陷,另外的话更要注意的是between ...and语法是两头都是闭区域间。上述语句如果ID连续不断地情况下,咱们最终得到的其实是11条数据,并不是10条数据,所以这个地方还是需要注意的。 存入到es中上述罗列的几种分页优化的方法其实已经够用了,那么如果数据量再大点的话咋整,那么我们可能就要选择其他中间件进行查询了,当然我们可以选择es。那么es真的就是万能药吗?显然不是。ES中同样存在深度分页的问题,那么针对es的深度分页,那么又是另外一个故事了,这里咱们就不展开了。 写到最后那么半夜三更爬起来优化慢查询的小猫究竟有没有解决问题呢?电脑前,小猫长吁了一口气,解决了! select * from InventorySku isk inner join (select id from InventorySku where inventoryId = 6058 limit 109500,500 ) as d on isk.id = d.id 显然小猫采用了inner join的优化方法解决了当前的问题。 相信小伙伴们后面遇到这类问题也能搞定了。 转自https://www.cnblogs.com/kdaddy/p/18270217 作者程序员老猫 该文章在 2024/9/9 9:37:58 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886