SELECT sales_manager, product_category, unit_price FROM dummy_sales_data WHERE sales_manager IN (SELECTDISTINCT sales_manager FROM dummy_sales_data WHERE shipping_address = 'Germany' AND unit_price > 150) AND product_category IN (SELECTDISTINCT product_category FROM dummy_sales_data WHERE product_category = 'Healthcare' AND unit_price > 150) ORDERBY unit_price DESC;
WITH SM AS (SELECTDISTINCT sales_manager FROM dummy_sales_data WHERE shipping_address = 'Germany' AND unit_price > 150), PC AS (SELECTDISTINCT product_category FROM dummy_sales_data WHERE product_category = 'Healthcare' AND unit_price > 150) SELECT sales_manager, product_category, unit_price FROM dummy_sales_data WHERE sales_manager IN (SELECT sales_manager FROM SM) AND product_category IN (SELECT product_category FROM PC) ORDERBY unit_price DESC ;
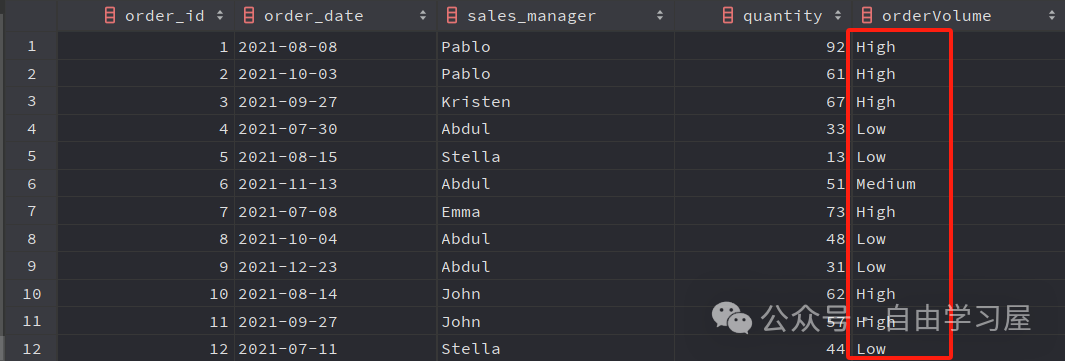
SELECT order_id, order_date, sales_manager, quantity, CASE WHEN quantity > 51THEN'High' WHEN quantity < 51THEN'Low' ELSE'Medium'ENDAS orderVolume FROM dummy_sales_data;
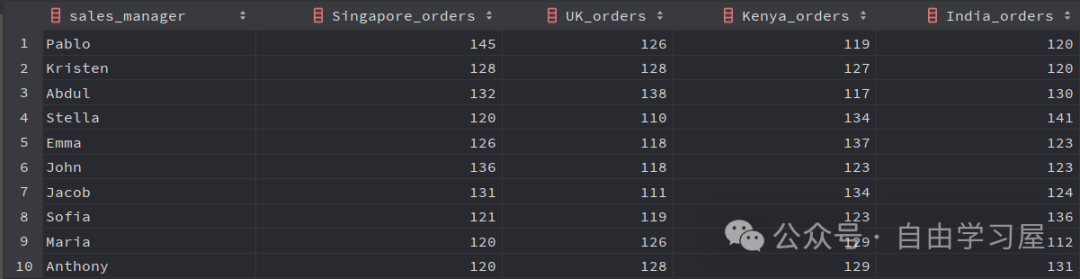
SELECT sales_manager, COUNT(CASE WHEN shipping_address = 'Singapore'THEN order_id END) AS Singapore_orders, COUNT(CASE WHEN shipping_address = 'UK'THEN order_id END) AS UK_orders, COUNT(CASE WHEN shipping_address = 'Kenya'THEN order_id END) AS Kenya_orders, COUNT(CASE WHEN shipping_address = 'India'THEN order_id END) AS India_orders FROM dummy_sales_data GROUPBY sales_manager;
使用 CASE..WHEN..THEN,我们为每个运送地址创建了单独的列,以获得以下期望的输出:
根据你的使用情况,你也可以与 CASE 语句一起使用不同的聚合函数,如 SUM(总和)、AVG(平均值)、MAX(最大值)、MIN(最小值)。
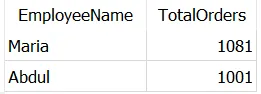
SELECT t1.EmployeeName, t1.TotalOrders FROM Dummy_Employees AS t1 JOIN Dummy_Employees AS t2 ON t1.ManagerID = t2.EmployeeID WHERE t1.TotalOrders > t2.TotalOrders;






 400 186 1886
400 186 1886



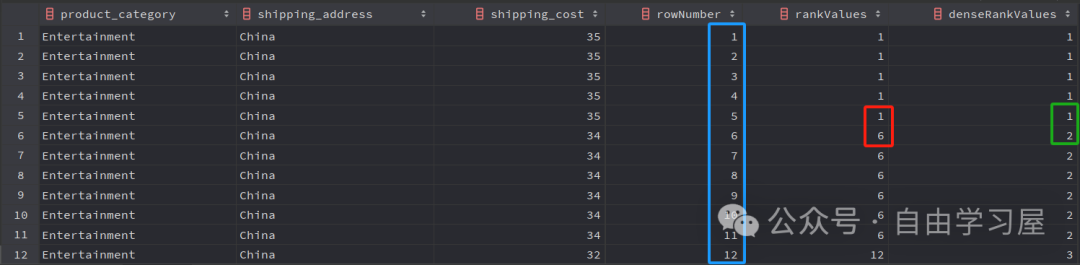

 根据你的使用情况,你也可以与
根据你的使用情况,你也可以与