如何使用.NET在2.2秒内处理10亿行数据(1brc挑战)
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
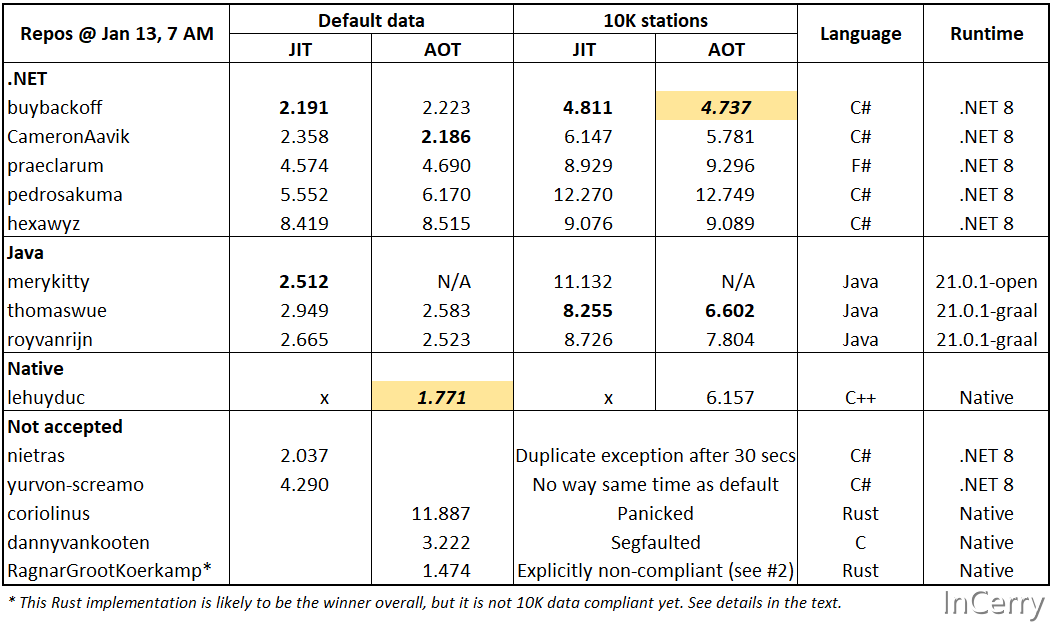
译者注#在上周我就关注到了在github上有1brc这样一个挑战,当时看到了由Victor Baybekov提交了.NET下最快的实现,当时计划抽时间写一篇文章解析他的代码实现,今天突然看到作者自己写了一篇文章,我感觉非常不错,在这里分享给大家。 这篇文章是关于.NET开发者Victor Baybekov参加的一个名为"One Billion Row Challenge"的编程挑战,他使用.NET语言编写了一个实现,这个实现的性能不仅打败了Java,甚至超过了C++。 这个挑战的目标是处理一亿行数据,并提供对数据的快速查询。原始版本只允许Java参与,但其他语言的开发者也希望参与其中,因此挑战对其他语言开放。Victor Baybekov的实现不仅在特定的数据集上表现优秀,而且在处理更通用的数据上也表现出色。他使用.NET的原因是,它的运行速度快且易于使用。 文章中,Victor Baybekov详细介绍了他的优化过程,包括使用内存映射文件,优化哈希函数,使用输入规范,使用自定义字典,优化内部循环等。他还强调了.NET的速度和易用性,同时提到了.NET提供的不安全选项,并不会使代码自动变得不安全。 对于.NET开发者来说,这篇文章提供了很多关于如何优化代码性能的实用信息。对于非.NET开发者来说,这篇文章也是一次了解.NET强大性能的好机会。 总的来说,这篇文章非常专业,为.NET开发者提供了一种思路,即通过使用.NET的功能和优化代码,可以实现非常高的性能。同时,这篇文章也证明了.NET在处理大量数据时的优秀性能和易用性。 正文#在处理真实输入数据时,.NET平台上的十亿行挑战比Java更快,甚至比C++还要快。 上周,GitHub上因为Gunnar Morling发起的“十亿行挑战”而热闹非凡。最初这是一个仅限Java参与的比赛,但后来其他语言的开发者也想加入这场乐趣。如果你不了解这个挑战及其规则,请先阅读这些链接。 https://github.com/gunnarmorling/1brc https://github.com/gunnarmorling/1brc/discussions/categories/show-and-tell 我也被这个挑战深深吸引了。截至撰写本文时,我编写的是目前最快的托管1BRC实现版本,它不仅在大家优化的特定数据集上表现出色,而且在更通用的数据上也有很好的性能。更重要的是,我的结果在默认数据上非常接近整体最优的C++版本,并且在通用数据的情况下超过了它。 https://github.com/buybackoff/1brc 在下面的“结果”部分,我展示了不同语言和数据集的不同计时结果。在 “我的#1BRC之旅” 中,我展示了我的优化历程和性能时间线。然后我讨论了为什么.NET在编写这类代码时既快速又易用。最后,我描述了我如何在日常工作中编写高性能的.NET代码,并邀请你如果对现代且快速的.NET感兴趣,就来申请加入我们。 结果#除了我的代码之外,我还在我的家庭实验室中专门搭建了一个基准测试服务器。它拥有固定的CPU频率并且能够提供非常稳定的结果。我投入了大量的精力来比较不同实现的性能。对于.NET和Java,我测量了同一代码的JIT和AOT性能。 我没有添加排名,因为结果会根据数据的不同而有所不同。我用粗体突出显示了按语言/JIT-AOT/数据集分组的最佳结果,并用黄色背景突出显示了按数据集分组的整体最佳结果。
可能如预期的那样,C++对于默认数据集来说是最快的。然而,C++与.NET和Java之间的细微差别,即便是我也觉得有些出乎意料。我确实预料到了.NET会击败Java。这并非是第一次发生这种情况。在2016年,Aeron.NET客户端1.0版本就比Java快,我当时就在现场。 至于Rust,它很可能会成为总体的领导者。我们只需要等待直到实现是正确的。在撰写本文时,它还没有做到。 最终,所有结果应该会趋于某个物理极限和理想的CPU利用率。那么,一个有趣的问题将是,开发这样的代码付出了什么代价。对我来说,达到当前这个点相当容易,而且代码非常简单。 扩展数据集#默认的数据生成器只有少量气象站名称,最大长度低于AVX向量大小。这两个属性都有助于带来极端的性能提升。然而,规格说明中提到,可能有多达1万个独特的气象站,它们的名称最多包含100个UTF8字节。
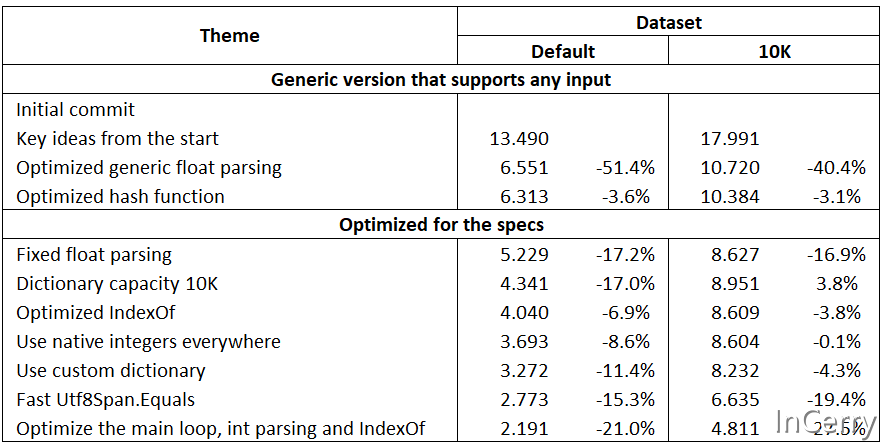
为了更公平的比较,我使用了两个数据集: 原始的默认数据集是用 扩展的数据集包含了1万个随机的气象站名称,长度可以达到规格所允许的最大值。它是用 在表格的底部,你可以看到一个单独的部分,用于展示那些在默认数据集上表现良好但无法正确处理1万个数据的结果。这表明这些实现使用了超出规则说明的一些假设,并且不公平地过度优化了特定的情况。例如,最快的Rust版本的作者明确表示它不适用于1万个数据。他更喜欢先编写快速的代码,然后再使其正确。 就我而言,我努力从一开始就编写最通用的代码。名称可以是任意长度,数字可以是任意非科学计数的浮点数,行尾可以是 在Java再次变得更快之后(也是在短时间内),我查看了规则,但没有查看数据。对我来说,数字范围的限制是最重要的,但气象站名称仍然可以是任意长度。代码会处理冲突,但对于真实世界输入的气象站名称应该很少发生冲突。不过我必须承认,有可能创建人为数据,这些数据将会发生冲突,并将O(1)的哈希表查找变成O(N)的线性搜索。但即使在这种情况下,它仍然会工作,并且可能比参考实现还要快。也许我稍后会为了好玩而尝试这样做。 方法论#性能测试是在一个安静的6C/12T Alder Lake CPU上进行的,该CPU的频率固定在2.5 GHz(关闭睿频功能),搭配32GB DDR4 3200内存,运行Debian 12系统,并且在Proxmox的特权LXC容器中进行测试。由于基准频率是固定的,散热状况非常好(< 35°C),即使在持续100%负载下也不会发生降频现象。 时间测量使用了 对于前两名的.NET结果,我多次运行了基准测试,甚至为此重新启动了机器。确实,在默认数据上,根据JIT与AOT的不同,它们的排名有所不同。对于我的代码来说,AOT略有不利,但对于Cameron Aavik的代码来说,AOT显著提高了性能。 我的#1BRC之旅#我咳嗽已经超过2周了。新年期间咳得很厉害,以至于我在1月2日到3日请了假。1月3日,我喝着加了姜和蜂蜜的热茶,刷着Twitter。我看到了Kevin Gosse关于这个挑战的推文,我很喜欢这个想法。但我也清楚,这可能是一条通向深不见底的迷宫的入口,在那迷宫的底部,隐约能感受到曾经浪费时间的回忆。 然而,任务非常简单。我决定测量一下我写一个非常简单但仍然快速的实现需要多长时间。当时是下午1:01,到下午3:17,我就完成了第一个版本,在我的测试机上处理默认数据集/10K数据集分别需要13.5/18.0秒。然后,我开始疯狂地优化它。 通用版本,适用于任何输入#起初,我甚至没有尝试针对规格进行优化。只是一个名称和一个浮点数,中间用分号隔开,每行一个测量值,在Linux上以 关键Idea#提交时的文件: https://github.com/buybackoff/1brc/tree/f1b81f8a590a8a42d5be8358e6ba30489e678592/1brc 与上一版本的差异: https://github.com/buybackoff/1brc/compare/82a17bc..f1b81f8?diff=split&w= 时间:13.490 / 17.991 (10K) 我的实现的关键思想直到最后都没有改变。魔鬼隐藏在最微小的细节中。 内存映射文件#使用mmap是显而易见的,因为我之前在高性能场景下多次使用它,比如IPC环形缓冲区。它非常简单易用,所有复杂性都由操作系统管理。最近数据库社区就是否使用mmap还是手动内存管理,即LMDB与其他方式之间进行了激烈的讨论。顺便说一句,我是LMDB的大粉丝,甚至为其编写了最快的.NET封装。 尽管如此,为了避免munmap的慢速时间,我在这里尝试了不使用mmap的方法。结果确实慢了一些,但并不太多。仅将文件复制到内存中最多需要大约200毫秒的CPU带宽,再加上不可避免的开销,这就很能说明问题了。 Utf8Span#
public readonly unsafe struct Utf8Span : IEquatable<Utf8Span>{
private readonly byte* _pointer;
private readonly int _len;
// 构造器
public ReadOnlySpan<byte> Span => new ReadOnlySpan<byte>(_pointer, _len);
public bool Equals(Utf8Span other) => Span.SequenceEqual(other.Span);
// 真是太懒了!连_hash中免费可用的额外熵都没用上。
// 但它在默认数据集上运行得相当不错。
public override int GetHashCode()
{
// 使用前几个字节作为哈希值
if (_len > 3) return *(int*)_pointer;
if (_len > 1) return *(short*)_pointer;
if (_len > 0) return *_pointer;
return 0;
}
public override bool Equals(object? obj) => obj is Utf8Span other && Equals(other);
public override string ToString() => new string((sbyte*)_pointer, 0, _len, Encoding.UTF8);}为了高效地进行哈希表查找,
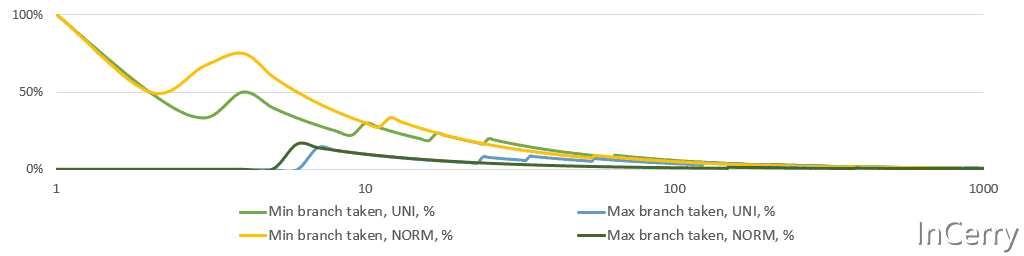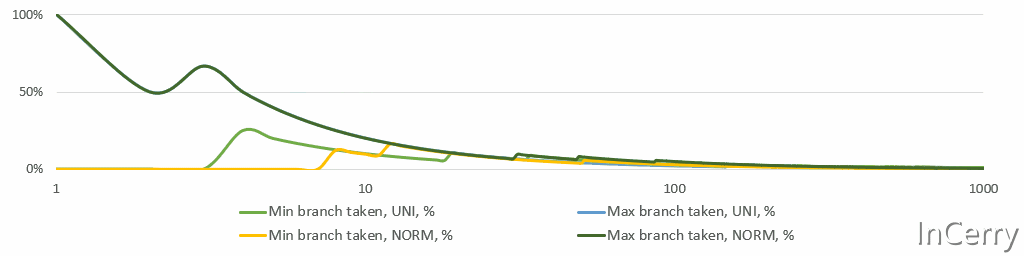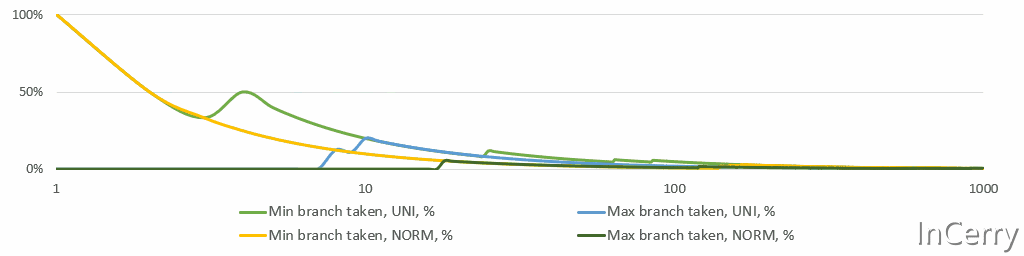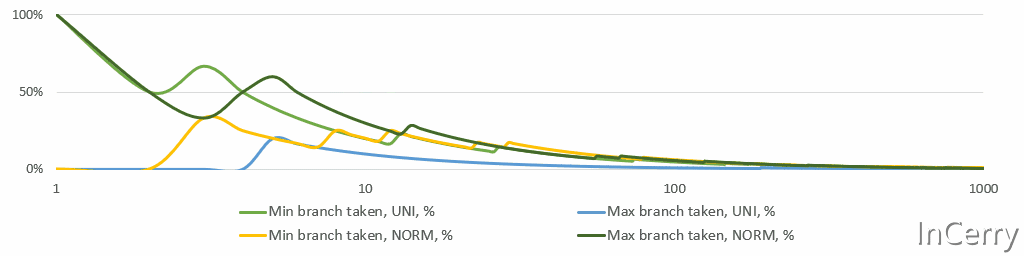
平均值/最小值/最大值的高效更新#要计算运行平均值,我们需要存储总和和计数。这里没有什么有趣的,我们都知道,自从编程幼儿园时代起,不是吗? 更新 最小值/最大值 在数学上甚至更简单。只需检查新值是否 小于/大于 之前的 最小值/最大值 ,并相应地更新它们。然而,CPU不喜欢if语句,分支预测错误的成本很高。然而,如果你再多想一点从统计学角度来看,对于任何稳定的过程,实际上覆盖 最小值/最大值 的机会随着每一次观测迅速下降。即使是股票价格,它们不是稳定的,也不会每天、每月或每年都达到历史新高。温度据说“平均来说”是稳定的,并且至少在几个世纪的尺度上是稳定的。 下面是一个简单的模拟,显示了 最小值/最大值 分支所占比例的运行情况。请注意,X轴是对数的。平均来说,仅在10次观测后,两个分支都不会被采用。
最小值/最大值分支概率#这个分析告诉我们使用分支而不是更重的无分支位运算。我最终尝试了无分支的选项,但我有统计直觉,并且在第一个以及最终实现中都使用了if语句。无分支代码使得执行变得后端受限(如 perf stat 所见)。 public struct Summary{
// 注意,最初它们甚至不是浮点数
public double Min;
public double Max;
public double Sum;
public long Count;
public double Average => Sum / Count;
public void Apply(double value, bool isFirst)
{
// 第一个值总是会更新最小值/最大值
if (value < Min || isFirst)
Min = value;
if (value > Max || isFirst)
Max = value;
Sum += value;
Count++;
}}.NET 默认字典#
还有一个非常好但不广为人知的高性能工具类 通过取得摘要值的引用,我们避免了将其复制和更新到栈上/栈中,然后使用常规 API 再复制回字典。记住, // 没有结构体复制 ref var summary = ref CollectionsMarshal.GetValueRefOrAddDefault(result, nameUtf8Sp, out bool exists); // 对于类:分支、分配、代码大小。谢谢,不用了。在 .NET 中,值类型规则。 // if (summary is null) summary = new Summary(); summary.Apply(value, !exists); // 这个方法在上面展示过 字节解析#对于解析字节,我只是使用了 .NET 的 其他一切#性能仅取决于每个线程内的 我很惊讶有些人准备就仅仅使用 (P/)LINQ 的事实进行争论,仅仅因为他们听说它很慢。他们显然不够了解 .NET,也没有区分热路径和冷路径。 var result = SplitIntoMemoryChunks() // 将整个 mmap 分成每个 CPU 相等的块
.AsParallel().WithDegreeOfParallelism(_threads) // 分配到所有 CPU 核心
.Select((tuple => ProcessChunk(tuple.start, tuple.length))) // 在每个 CPU 上执行 ProcessChunk 工作。
.Aggregate((result, chunk) => { /* 合并结果 ... */ })
;优化的浮点数解析#提交时的文件: https://github.com/buybackoff/1brc/tree/273def1abf9c9cc365b4309a3bd8d081a3eb7951/1brc 与上一版本的差异: https://github.com/buybackoff/1brc/compare/f1b81f8..273def1?diff=split&w= 时间:6.551 / 10.720 (10K) 在对代码进行性能分析后,我发现 我添加了一个通用的浮点数解析器,它有一个快速路径,但在检测到任何不规则情况时会回退到原始方法。所有的 这几乎使性能翻了一番!还有一些其他的微优化,只需点击每个部分开头的“与上一版本的差异”链接,即可查看所有更改。 [MethodImpl(MethodImplOptions.AggressiveInlining)]private double ParseNaive(ReadOnlySpan<byte> span){
double sign = 1;
bool hasDot = false;
ulong whole = 0;
ulong fraction = 0;
int fractionCount = 0;
for (int i = 0; i < span.Length; i++)
{
var c = (int)span[i];
if (c == (byte)'-' && !hasDot && sign == 1 && whole == 0)
{
sign = -1;
}
else if (c == (byte)'.' && !hasDot)
{
hasDot = true;
}
else if ((uint)(c - '0') <= 9)
{
var digit = c - '0';
if (hasDot)
{
fractionCount++;
fraction = fraction * 10 + (ulong)digit;
}
else
{
whole = whole * 10 + (ulong)digit;
}
}
else
{
// 遇到任何不规则情况就回退到完整实现
return double.Parse(span, NumberStyles.Float);
}
}
return sign * (whole + fraction * _powersPtr[fractionCount]);}优化的哈希函数#提交时的文件: https://github.com/buybackoff/1brc/tree/e23c2bf8dace1450ad0411feaf54488795ec0fcb/1brc 与上一版本的差异: https://github.com/buybackoff/1brc/compare/273def1..e23c2bf?diff=split&w= 时间:6.313 / 10.384 (10K) 它不再像初始版本那样懒惰,它包含了长度和最初的几个字节的组合。免费获得了超过3%的收益。 如果哈希总是零,我们使用线性搜索,有一些评论和最坏情况下的测量。 public override int GetHashCode(){
// 这里我们使用前4个字符(如果是ASCII)和长度来计算哈希。
// 最坏的情况是前缀,如 Port/Saint 且长度相同,
// 这对于人类地理名称来说相当罕见。
// .NET 字典显然会因为冲突而变慢,但仍然可以工作。
// 如果我们只保留 `*_pointer`,运行时间仍然合理,大约9秒。
// 仅使用 `if (_len > 0) return (_len * 820243) ^ (*_pointer);` 耗时5.8秒。
// 仅返回0 - 最糟糕的哈希函数和线性搜索 - 运行时间慢了12倍,为56秒。
// 魔术数字820243是包含2024的最大快乐素数,来自 https://prime-numbers.info/list/happy-primes-page-9
if (_len > 3)
return (_len * 820243) ^ (*(int*)_pointer); // 只添加了 ^ 之前的部分
if (_len > 1)
return *(short*)_pointer;
if (_len > 0)
return *_pointer;
return 0;}在这个改变之后,我开始研究哪些规则可能对性能有用。 使用输入规则#挑战的规则说明名字总是少于100个UTF8字节,最多有10K个独特的名字,温度在-99.9到99.9之间( 我认为针对规则进行优化是完全可以接受的。可能有真正的气象站产生这样的数据,而代码在我出生前就已经写好了。然而,我不喜欢人们开始针对特定的数据集/生成器进行优化。因此,在这次比较中,我没有接受那些不能处理10K数据集的实现。即使使用规格,我的代码也支持任何名字长度。 将数字解析为整数#提交时的文件: https://github.com/buybackoff/1brc/tree/e5d34c92a82a446d876089a1e1872da54bf64ebb/1brc 与上一版本的差异: https://github.com/buybackoff/1brc/compare/e23c2bf..e5d34c9?diff=split&w= 时间:5.229 / 8.627 (10K) 仅仅利用温度在-99.9到99.9之间的事实。我们只有4种情况,可以为此进行优化: ...;-99.9 ...;-9.9 ...;9.9 ...;99.9 设置字典容量#提交时的文件: https://github.com/buybackoff/1brc/tree/3644b251cda38abd620bda644efda12951020042/1brc 与上一版本的差异: https://github.com/buybackoff/1brc/compare/e5d34c9..3644b25?diff=split&w=# 时间:4.341 / 8.951 (10K) 这真是太傻了!但在我迫切需要提升性能的时候,这就像罐头食品一样珍贵。仅仅一行代码/改动五个字符就能获得17%的性能提升。 优化的IndexOf#提交时的文件: https://github.com/buybackoff/1brc/tree/7fdd17a755665910ecfabb4667b5bda277531e39/1brc 时间:4.040 / 8.609 (10K) 在剩余部分小于32字节时,手动AVX2在Span中搜索字节,并回退到 // 在 Utf8Span 内部 [MethodImpl(MethodImplOptions.AggressiveInlining)] internal int IndexOf(int start, byte needle) { if (Avx2.IsSupported) { var needleVec = new Vector<byte>(needle); Vector<byte> vec; while (true) { if (start + Vector<byte>.Count >= Length) goto FALLBACK; var data = Unsafe.ReadUnaligned<Vector<byte>>(Pointer + start); vec = Vector.Equals(data, needleVec); if (!vec.Equals(Vector<byte>.Zero)) break; start += Vector<byte>.Count; } var matches = vec.AsVector256(); var mask = Avx2.MoveMask(matches); int tzc = BitOperations.TrailingZeroCount((uint)mask); return start + tzc; } FALLBACK: int indexOf = SliceUnsafe(start).Span.IndexOf(needle); return indexOf < 0 ? Length : start + indexOf; } 积极的使用本机整数#提交时的文件: https://github.com/buybackoff/1brc/tree/d6c8e48b07821a05a1582f0e98f949360e3b4bd9/1brc 与上一版本的差异: https://github.com/buybackoff/1brc/compare/7fdd17a..d6c8e48?diff=split&w= 时间:3.693 / 8.604 (10K) 在本机环境中,使用size_t本机大小类型作为偏移和长度是正常的,因为CPU处理本机字更快。在.NET中,大多数公共API接受32位int。CPU必须每次将其扩展为nint。但内部.NET本身使用本机整数。 例如,这是带有注释的 // 优化的基于字节的SequenceEquals。这个的“length”参数被声明为nuint而不是int, // 因为我们也用它来处理除byte以外的类型,其中长度一旦通过sizeof(T)缩放就会超过2Gb。 [Intrinsic] // 对常量长度展开 public static unsafe bool SequenceEqual(ref byte first, ref byte second, nuint length) { bool result; // 使用nint进行算术运算以避免不必要的64->32->64截断 if (length >= (nuint)sizeof(nuint)) 使用自定义字典#提交时的文件: https://github.com/buybackoff/1brc/tree/8841e83e2abfb5f57a872cbea4c979c9b9e49178/1brc 与上一版本的差异: https://github.com/buybackoff/1brc/compare/d6c8e48..8841e83?diff=split&w= 时间:3.272 / 8.232 (10K) 直到这一点,我仍然使用的是默认的.NET字典。但由于规格说明最多有10K个独特的名字,我可以利用这个规则。 详细信息以后再补充。 快速 Utf8Span.Equals#提交时的文件: https://github.com/buybackoff/1brc/tree/9ed39221ec7db8f89e8e2a0702d43a184cc5e879/1brc 与上一版本的差异: https://github.com/buybackoff/1brc/compare/8841e83..9ed3922?diff=split&w= 时间:2.773 / 6.635 (10K) 我花了一些努力尝试击败 为了确保安全,我确保最后一个大块不是在文件末尾结束,而是至少在距离末尾 优化内循环#提交时的文件: https://github.com/buybackoff/1brc/tree/1051e06052d5a8a95fa0aee461e37d969532aa65/1brc 与上一版本的差异: https://github.com/buybackoff/1brc/compare/9ed3922..1051e06?diff=split&w= 时间:2.204 / 4.811 (10K)
详细信息待定 性能时间线#以下是讨论上述每次更改后性能演变的时间线。
.NET 非常快#.NET 非常快。而且每个新版本都在变得更快。有些人开玩笑说,对于 .NET 的最佳性能优化就是更新它 - 对于大多数用户来说,这可能是真的。 每次发布新版本时,.NET 团队的 Stephen Toub 都会发表一篇巨大的博客文章,介绍自上次发布以来的每一个微小性能改进。这些文章的庞大体量表明,他们非常关心性能的提升。 不安全代码#.NET 允许你直接使用指针。这使得它类似于 C 语言。如果内循环受 CPU 限制,所有数组都可以被固定并在没有边界检查的情况下访问,或者我们可以直接像在这个 1BRC 案例中那样直接处理本地内存。 另外,.NET 提供了一个较新的 Unsafe 类,它本质上与旧的 unsafe 关键字 + 指针做同样的事情,但使用托管引用。这允许跳过固定数组,同时仍然是 GC 安全的。 不安全选项的存在并不会自动使代码不安全。有“不安全的 Unsafe”和“安全的 Unsafe”。例如,如果我们确保数组边界,但不能使 JIT 省略边界检查(如在自定义字典案例和 易用的向量化函数#.NET 有非常容易使用的 SIMD 内在函数。我们可以直接使用 SSE2/AVX2/BMI API,或者使用跨平台跨架构的 .NET 的范围#.NET 不强迫我们每次都编写低级的不安全 SIMD 代码。当性能不重要时,我们可以只使用 LINQ。这很好。即使在这个 1BRC 挑战中也是如此。真的。 C# 与 F##F# 在默认数据集和10K数据集上都展现出了不俗的性能。我与 F# 的关系颇为复杂。博客上的一篇长篇文章讲述了我为何放弃 F# 转而选择 C# 的原因。主要是因为性能问题(包括生成的代码和工具的性能),尽管我喜欢 F# 的语法和社区。 然而,F# 的速度之快并不让我感到惊讶。它一直在稳步提升,或许有一天我会再次使用 F#. 例如,可恢复代码和可恢复状态机是我一直在关注的非常强大的功能。.NET 原生支持的 在这里,我不得不提到,我也通过一系列在2020年的提交,大幅提高了 F# 性能,使其核心的 当然,正如作者所承认的,Frank Krueger 的 F# 实现远非典型的函数式 F# 代码。但是,如果你已经在使用 F# 代码,而且不想碰 C#,你也可以在 F# 中写类似 C 的代码。只是不要过度,把它隐藏在纯函数里,然后对外保密。 😉 高性能 .NET 代码作为日常工作#在 ABC Arbitrage,我有机会每天都处理性能关键的 .NET 代码。公司多年前从 C++ 迁移到 .NET,这在可维护性、灵活性、性能和成本方面都是巨大的成功。像1BRC中看到的优化在我们的代码中并不少见。当然,并非我们所有的代码都是那样的。我们还有很多易读的现代 C# 代码,甚至 LINQ 也不是禁止的,除非它在交易路径上。我们总是跟上最新的 .NET 发展,通常在新的主要版本发布后几周内就会在生产环境中使用(例如,我们已经“长时间”使用 .NET 8 了)。 我们在 ABC 使用并贡献了许多开源项目,并且我们也维护一些。由 Olivier Coanet 维护的著名高性能线程间消息传递库 Disruptor-net 的 .NET 移植版本是我们交易平台的核心,处理着每一个市场行情和每一个交易订单。我贡献了一些类似上文讨论的微优化。由 Lucas Trzesniewski 作为主要贡献者的轻量级点对点服务总线 Zebus,自2013年以来一直在 ABC Arbitrage 的生产环境中运行,每天处理数亿条消息,并协调整个基础设施。由 Lucas、Romain Verdier 和其他人贡献的日志库 ZeroLog,速度之快且零分配,以至于我们甚至可以在最延迟敏感的路径上轻松使用它。公司仓库中还有其他项目,以及我们现任和前任同事的许多其他贡献。我们真正拥抱开源 😍 如果你喜欢使用现代 .NET 编写高性能代码,并且想在巴黎享受一点乐趣,为何不加入我们呢?我们有几个开放的 .NET 职位。如果你感到冲动,就在 dotnet📧abc-arbitrage.com 向我们发送申请吧。
原文信息#原文链接:https://hotforknowledge.com/2024/01/13/7-1brc-in-dotnet-even-faster-than-java-cpp/ 转自博客园https://www.cnblogs.com/InCerry/p/17964592/7-1brc-in-dotnet-even-faster-than-java-cpp 该文章在 2024/1/29 10:43:36 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886